
The Emergence of AI Assistants: Navigating the Landscape of ChatGPT, Llama, Claude, and China's Enigmatic Arrival
In late 2022, the tech world was abuzz with the release of ChatGPT by OpenAI. It demonstrated an unprecedented level of conversational ability that mimicked human interaction, making this AI chatbot a significant milestone in natural language processing. The advent of ChatGPT not only stirred excitement but also raised pertinent questions regarding the future implications of AI technology.
ChatGPT, while not pioneering the language model domain, was instrumental in thrusting AI assistants into the limelight. Its arrival has since put established tech giants on alert, encouraging them to harness this new technology. There has been plenty of speculation, with some even forecasting ChatGPT's potential to rival the likes of Google someday.
Fast forward to late 2023, and the competitive landscape is evolving rapidly. The quest to build upon ChatGPT's success has intensified, with major corporations like Meta and emerging startups such as Anthropic unveiling their own versions of AI chatbots. Each iteration brings with it incremental advancements in the realm of chatbot technology.
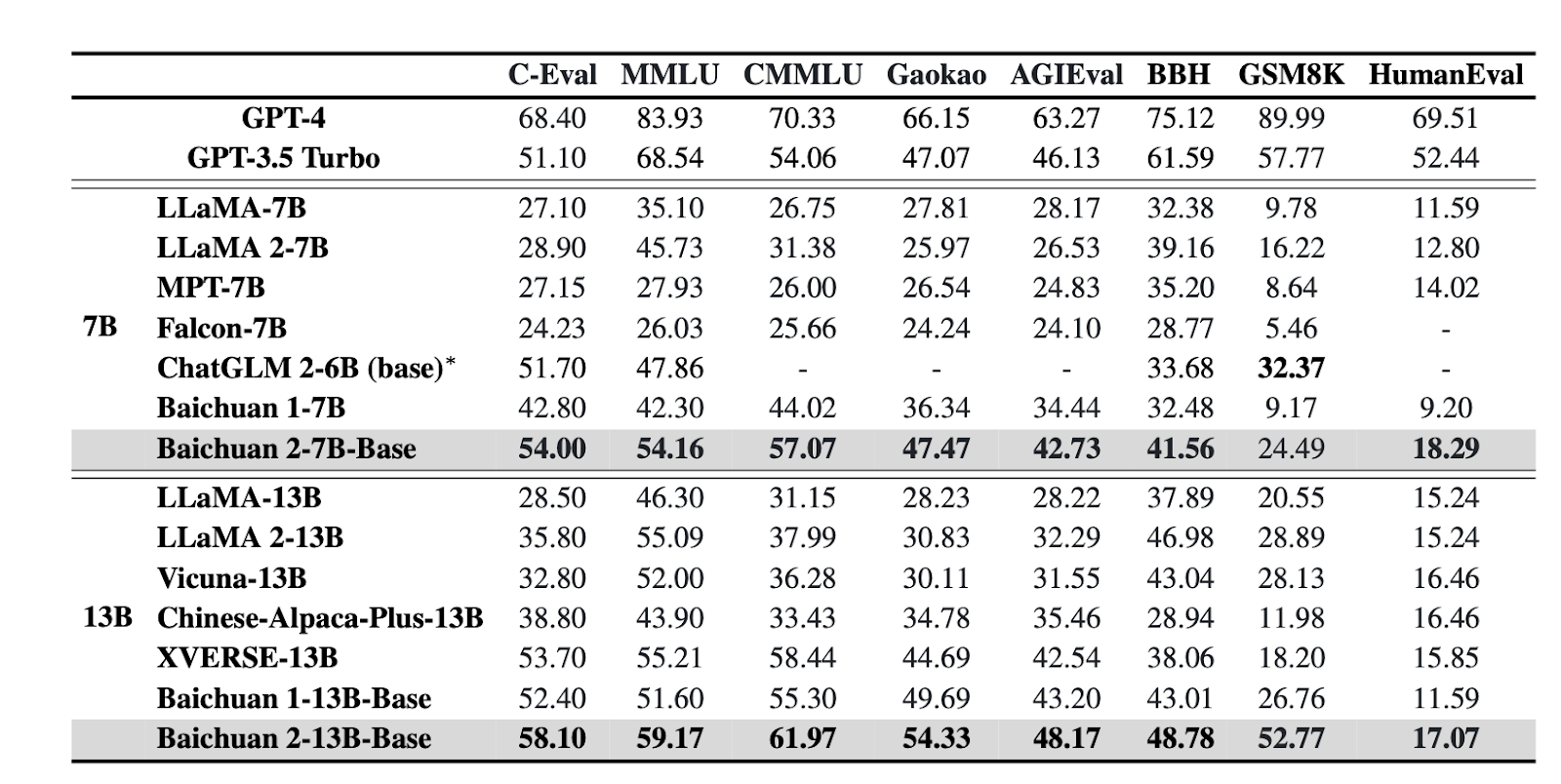
Amidst the fervor surrounding these new offerings trying to surpass ChatGPT's conversational capabilities, a dark horse has discreetly entered the arena from China—Baichuan, a new open-source language model that's gaining popularity among developers and users alike. It competes directly with LLaMA 2, the current most used model, and stands out for its ability to process and generate text in multiple languages, including Chinese and English. Unlike most open-source large language models that focus primarily on English, Baichuan is designed to handle a wide range of languages, making it a promising tool for breaking language barriers. As the race to build the best LLM continues, one key aspect that sets these models apart is their performance in benchmarking tests. Benchmarking is the process of evaluating a model's performance on a specific task or set of tasks, allowing developers and users to compare the strengths and weaknesses of different models.
In the context of LLMs, benchmarking tests assess a model's ability to understand and respond to natural language inputs in a way that is both accurate and engaging. This includes tasks such as conversational dialogue, natural language processing, and text generation, as well as more specialized tasks like code generation, math solving, and problem-solving.
The importance of benchmarking cannot be overstated, as it provides a standardized way to evaluate the effectiveness of different models and identify areas for improvement. By comparing the grades achieved by various models in benchmarking tests, we can gain valuable insights into their strengths and weaknesses, and ultimately determine which model is the best fit for a particular use case.
Assessing Model Effectiveness Through Benchmarking
Before we start to dive into the benchmarking, let us clarify the different areas and what they mean:
- MMLU - Tests language understanding across multiple languages.
- GSM8K - Evaluates mathematical reasoning through grade school math problems.
- HumanEval - Measures how human-like a model's responses are.
- C-Eval - Assesses logical reasoning and common sense.
- AGI Eval - Benchmarks models across cognitive skills like logic, knowledge, language.
- CMMLU - Extends MMLU to test understanding across text, images, audio, video.
- GRE Reading - Evaluates reading comprehension using GRE verbal test questions.
- GRE Writing - Tests essay writing skills using the GRE analytical writing assessment.
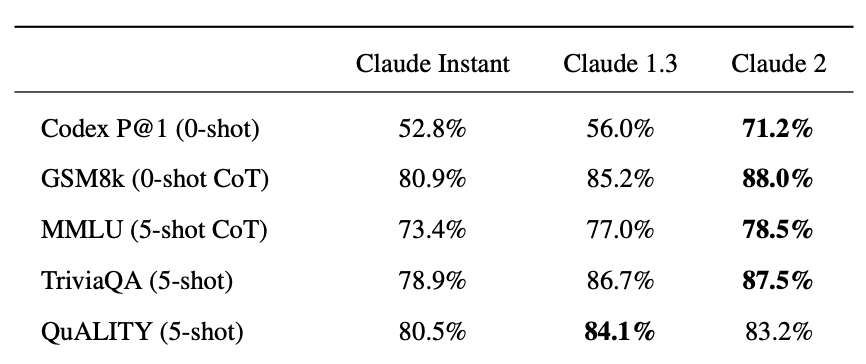
For natural language understanding, LLama 2 scored 68.9% on the MMLU benchmark, demonstrating its top abilities for processing human-like text. Claude 2 also excels in language, achieving 78.5% on MMLU.
When it comes to mathematical reasoning, GPT-4 leads, scoring 92% on the GSM8K math benchmark. Claude 2 also did respectably with 88% on GSM8K math, but trails GPT-4 in this area specifically.
For essay writing proficiency, Claude 2 stood out by scoring in the 96th percentile on the GRE analytical writing test, showing its specialized strength in generating high-quality written arguments.
In advanced reasoning tests like C-Eval (58.1%) and AGI Eval (54.3%), Baichuan kept pace surprisingly close to GPT-4, despite weaker English skills. This suggests a unique promise in Baichuan for reasoning.
In summary, each model has areas where it excels based on its training and architecture. LLama 2 demonstrates top language abilities, GPT-4 leads in mathematical logic, Claude 2 generates remarkably human-like writing, and Baichuan shows encouraging reasoning potential. No model is singularly "best" - they have complementary strengths suitable for different tasks and applications.
Models Safety and Oversight
Although all models are considered safe to use, there are varying degrees of safety within the AI community. Models are typically evaluated based on their helpfulness and harmfulness.
Helpfulness refers to the extent to which a model's responses fulfill a user's request and provide the requested information. For example, a model that provides detailed instructions on how to make a bomb may be considered helpful in a certain context, but it is clearly unsafe for society as a whole.
This distinction matters because AI has become a powerful tool for improving productivity, but it can also be used for malicious purposes. As a result, some companies and their founders have implemented safety guidelines to ensure that their models are trained to answer questions safely. Others, on the other hand, believe that users should have the freedom to ask for whatever they want, without fear of censorship.
OpenAI, along with Claude, Baichuan, and Llama, have made significant efforts to improve the safety and reliability of their language models. While OpenAI has not made as much data available, Baichuan and Llama have open-sourced their models, which has allowed for greater transparency and collaboration in the community. This openness has enabled researchers to extensively fine-tune these models, leading to safer and less harmful versions.
In this conversation, we will focus primarily on the models developed by Baichuan, Claude, and Llama, while acknowledging the contributions of OpenAI.
Llama 2
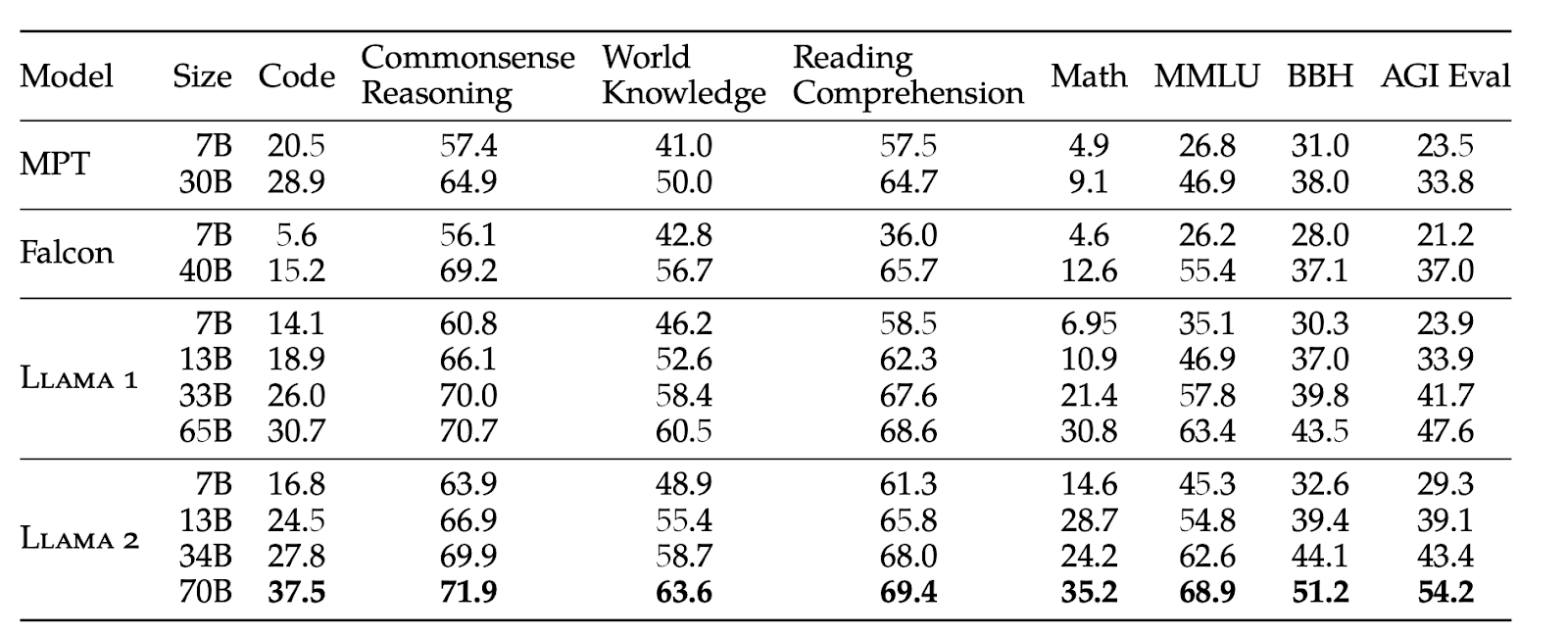
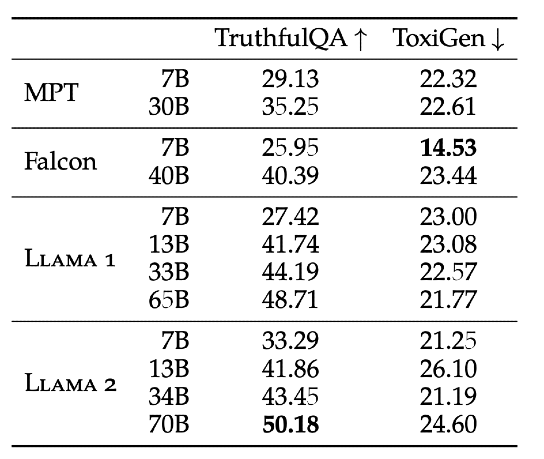
Meta has carried out extensive fine-tuning and reward modeling, testing various models with different parameters including 7, 13, 34, and 70B. Initially, the results were not as anticipated, but with persistent effort, significant improvements were seen. It is reflected in the Truthful QA ( evaluate the truthfulness of language models), and ToxiGen (assess the robustness of hate speech detection) scores, which display a marked reduction for the fine-tuned Llama 2-Chat. Notably, for the 70B parameter, truthfulness increased from 50.18 to 64.14 and toxicity decreased from 24.60 to 0.01. Moreover, the percentage of toxic generations effectively dropped to 0% for all sizes of Llama 2-Chat, showcasing the lowest toxicity level since the start.
This commendable progress is the result of Llama 2's enhanced safety measures which include:
- Supervised fine-tuning: Utilizing safe demonstrations and adversarial prompts to steer the model towards safer and more preferred responses.
- Reinforcement learning from human feedback (RLHF): Further enhancing safety through a safety-specific reward model, rejection of unsafe responses, and the optimization of actions based on human feedback.
- Context distillation: Teaching the model with a safety message, then fine-tuning it without the prefix, which helps the model learn the safety context.
The system takes into account safety categories like criminal activities, harm/hate, and unqualified advice. The goal is to prioritize safety, explain risks to users, and provide useful information. As new risks are identified, guidelines are updated and refined.

See the difference in response after fine-tuning:

Baichuan
Similar to Llama 2, the developers of Baichuan have also focused on increasing safety while maintaining performance. Techniques like adversarial training and controlled generation are used to reduce potential harm. Evaluations show these safety alignment measures significantly improved Baichuan 2's harmlessness without hurting helpfulness.
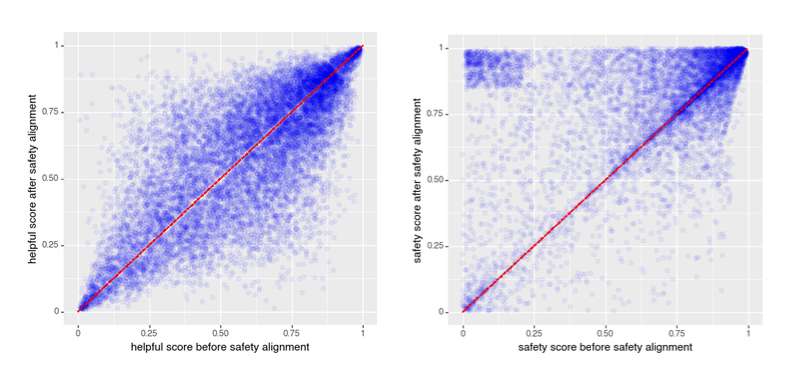
Another example, Baichuan 2 has lower toxicity scores on benchmarks like Toxigen compared to the original Baichuan model. Safety is approached holistically, involving steps like data filtering, model architecture changes, and objective adjustments during pre-training and fine-tuning. There is careful performance monitoring to ensure capabilities are not negatively impacted. The iterative process demonstrates it is possible to meaningfully improve safety without sacrificing helpfulness.

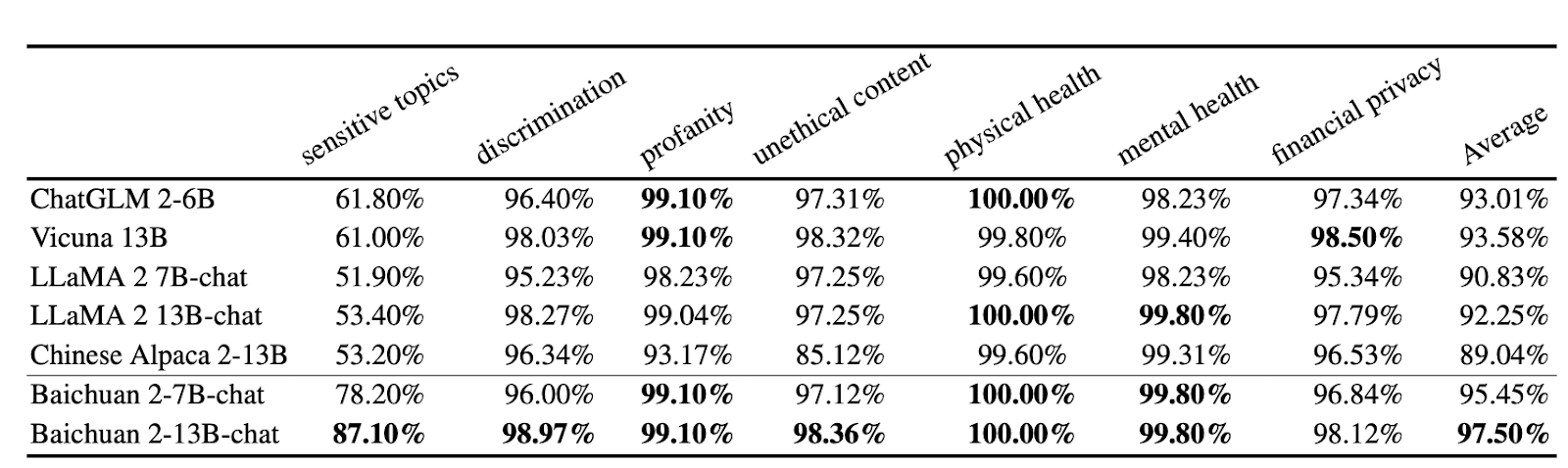
Ensuring safety is a critical priority as language models continue to advance. For example, both LLama 2 and Baichuan were recently evaluated on a comprehensive safety benchmark spanning 8 areas - sensitive topics, discrimination, profanity, unethical content, physical health, mental health, financial privacy, and more. The models achieved impressively high safety scores overall, with certain categories like physical health reaching 100% on the benchmark. This demonstrates the teams' commitment to holistic safety, going beyond just minimizing text toxicity to proactively address a wide range of potential harms. The high scores are a testament to continued research and engineering efforts to align language models with human values.
However, maintaining safety requires ongoing vigilance, transparency, and collaboration across the AI community as systems become more capable. Evaluating safety rigorously, and incrementally enhancing protections in lockstep with performance, will remain at the forefront for responsible language model development.
Claude 2
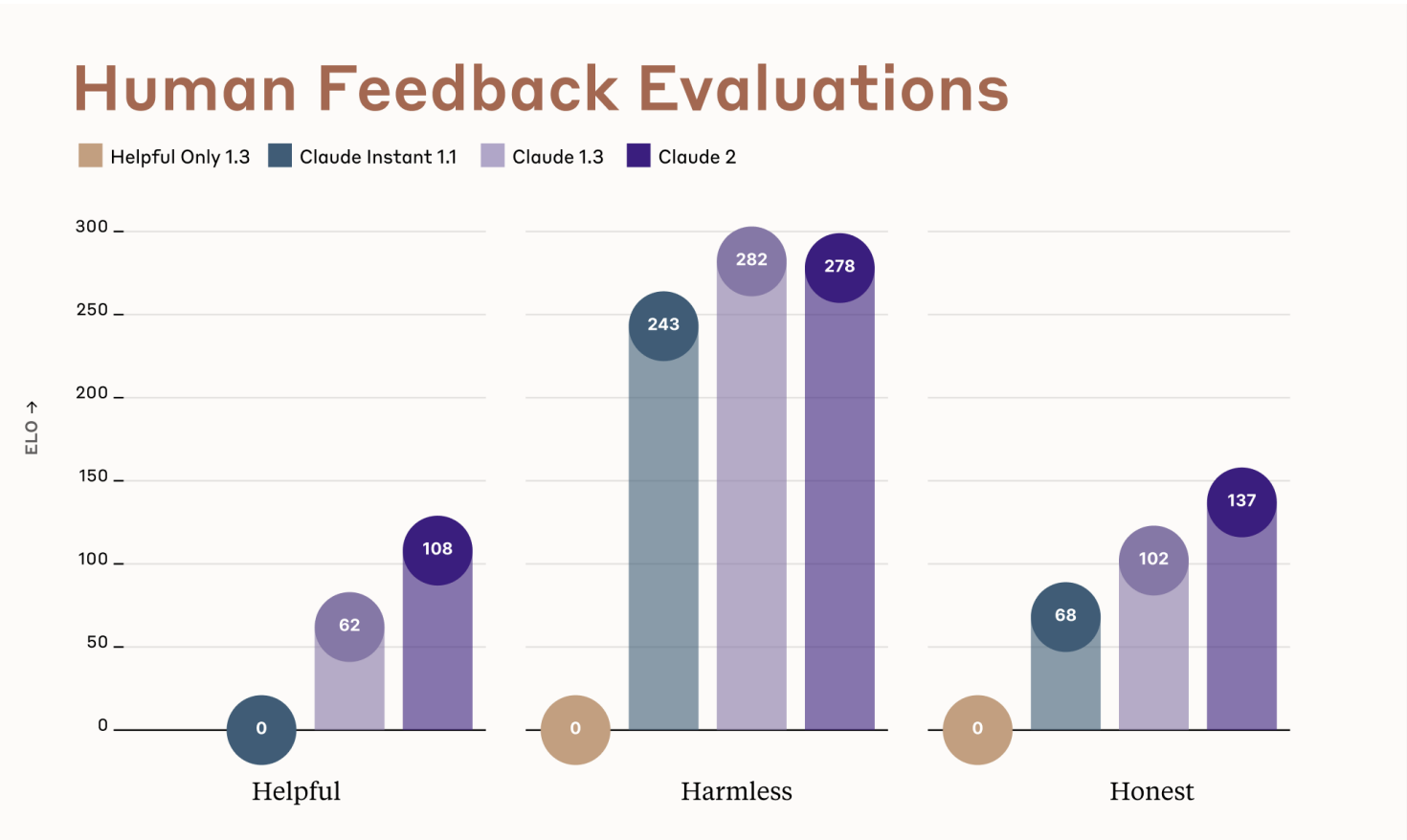
The Claude team uses human feedback to guide improvements to their AI system across conversational tasks like being helpful, harmless, and honest. They calculate comparative Elo scores based on humans judging the quality of Claude's responses.
Higher Elo scores indicate a version of Claude is preferred by humans over prior versions for a specific capability. For example, Claude 2 achieved an Elo score of 108 for helpfulness. This means in side-by-side tests, humans preferred Claude 2's responses over Claude 1 for helpfulness in 108 out of 100 hypothetical matchups.
Similarly, Claude 2's harmlessness Elo score of 278 means humans preferred its responses over Claude 1's for avoiding harm 278 out of 100 times. Its honesty score of 137 indicates humans chose its responses as more honest 137 out of 100 times when compared to Claude 1.
So in concrete terms, the higher Elo scores show Claude 2 generates noticeably more helpful, harmless, and honest responses according to human assessments. This human-in-the-loop evaluation process allows the Claude team to incrementally improve key conversational skills.
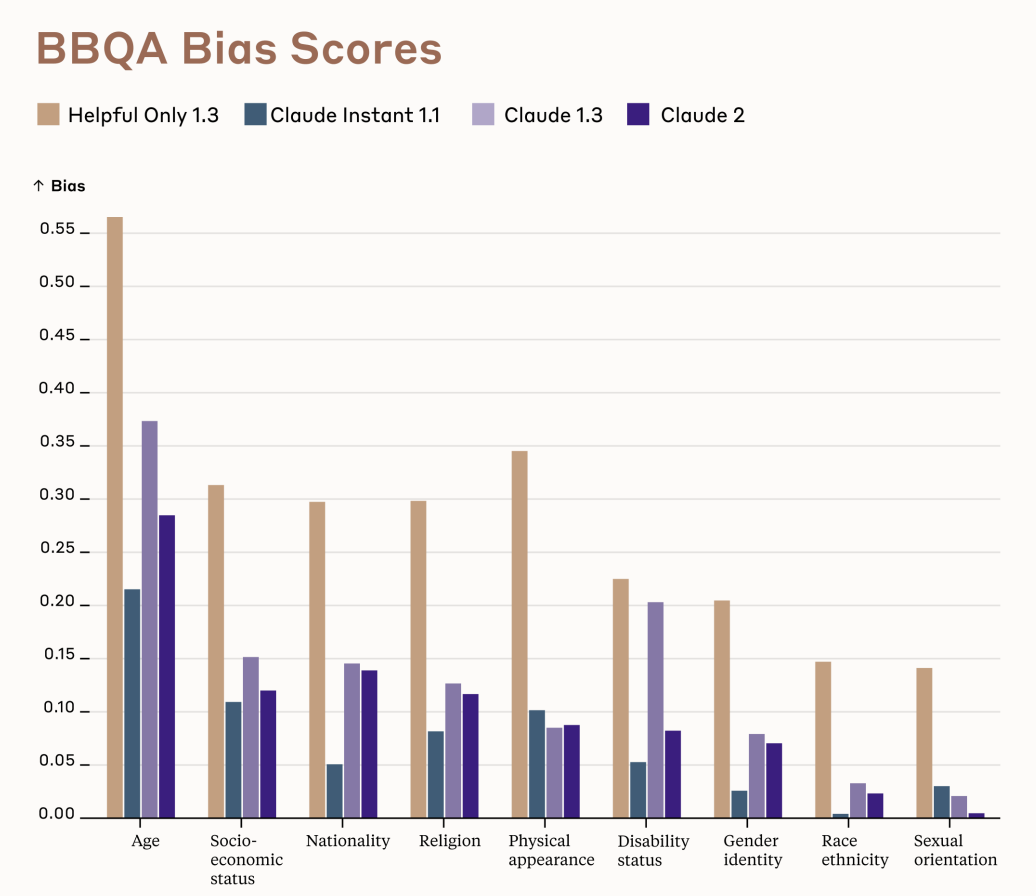
Another interesting data point to evaluate Claude's progress on safety is the Bias Benchmark for QA (BBQ). This benchmark measures stereotype bias across 9 social dimensions using ambiguous and disambiguated QA pairs. Results show Claude 2 has decreased bias compared to Claude 1 and helper-only models, likely reflecting improvements in Constitutional AI's debiasing algorithms used during training.
For instance, unbiased samples are generated and used to finetune Claude before reinforcement learning. The lower bias scores demonstrate Claude’s iterative approach has incrementally reduced biases through hard work and enhancing debiasing methods. However, continually evaluating performance on benchmarks like BBQ and finding ways to further improve will remain an important focus area for the team. Reducing societal biases is an ongoing process as algorithms and training practices continue advancing.
Openness in Models: Open-Source vs. Commercial
When comparing language models, it's important to consider their inherent nature and the approach behind their development. We cannot simply compare benchmark scores or safety features without understanding the underlying philosophy and objectives of each model.
- Accessibility: Open-source models provide unrestricted access to the code and weights, allowing developers to train, customize, and integrate them freely. Commercial models are often provided as a service with restricted access to the underlying code and limited customization options.
- Community Development: Open-source models foster collaboration and innovation within the AI community, allowing for collective development and improvement. Commercial models are typically controlled by a single entity, with limited community input.
- Customization and Training: Open-source models offer full customization and training capabilities, allowing developers to adapt them to specific needs. Commercial models have less flexibility in customization as training is handled by the provider.
- API Access and Tools: OpenAI has released developer-friendly tools like the embeddings API, while access to Claude's API might be more restricted.
- Philosophical Approach: Open-source projects aim to democratize AI and reduce barriers to entry, while commercial models are often part of a business model focused on sustainable revenue streams.
Pricing & Accessibility
Claude offers a free plan with limitations of 100 messages per 8 hours, while the paid plan grants continuous access for $20 per month. The pricing structure for the Claude 2 API is based on the number of words generated, costing around $0.0465 for 1,000 words. However, gaining access to Claude API can be challenging, as it requires filling out a form and waiting for a response which may take months.
OpenAI's free plan, limited to 3.5 turbo, allows for 20 requests per minute and 40,000 tokens per minute, the equivalent of approximately 8,000 to 10,000 words. This means that within a minute, you can input a text of up to 8,000 to 10,000 words into the API for processing. The plus version, priced at $20 per month, includes access to GPT-4, GPT-4 turbo, and plugins. OpenAI's API is relatively easy to access by providing credit/debit card information, with pricing varying depending on the specific model used.
Right now, if you want to start using Baichuan, you need to have a phone number from China. In addition, to get to use their API, you must apply with a Chinese business, which can be a bit tricky. But don't worry, OmniGPT plans to add Baichuan to their list of language models you can pick from pretty soon.
The cost of accessing Llama 2 can differ depending on the platform you choose, and it is influenced by aspects like the size of the model, how you plan to use it, and the service provider you select. Llama 2 itself does not come with a direct user interface for conversational interaction or for utilizing its various models. To use Llama 2, you can use it through OmniGPT. Within OmniGPT, the 7B and 13B versions of Llama 2 are available at no cost.
Where does OmniGPT stand in this race?
We think this race is very positive and it can only yield amazing benefits for people around the world. We aim to make all the advancements in the space accessible to our users so they can have the freedom to select the tools of their preference to achieve their goals.
We will continue to integrate new models and their different versions so our users can keep up with the latest trends in the AI space. Find out more on our site.
Conclusion
The landscape of AI-driven conversational models has undergone a significant transformation since the introduction of ChatGPT in late 2022. Subsequent models such as Meta's LLaMA 2, Anthropic's Claude, and the open-source Baichuan have further advanced the field of natural language processing. Each model has its unique strengths, with LLaMA 2 excelling in language understanding, GPT-4 in mathematical reasoning, Claude in essay writing, and Baichuan in reasoning capabilities.