
Llama 3: Meta's Next-Gen AI Model Takes on the Competition

With the release of Llama 3, Meta has thrown its hat into the ring of the rapidly advancing AI landscape. According to Chatbot Openarena benchmarks, Llama 3 is ranked among the top 5 language models, trailing close behind industry leaders like GPT-4 Turbo, GPT-4, Claude Opus, and Gemini Pro.
While competitors like OpenAI and Anthropic were making headlines with their model updates, Meta AI was quietly working behind the scenes on the next generation of Llama models. The release of Llama 3 marks a significant milestone in their ongoing efforts to advance the field of natural language processing.
Llama 3 builds upon the strengths of its predecessors, offering enhanced performance, improved efficiency, and expanded capabilities. With this latest iteration, Meta AI aims to solidify its position as a leading player in the LLM market, providing developers and researchers with a powerful tool to drive innovation and create groundbreaking applications.
Key Takeaways of Llama 3:
- It's Meta's biggest and most advanced AI model yet
- Ranks among the top 5 language models, just behind industry leaders
- Incorporates the latest data, keeping up with models like GPT-4 Turbo
- Trained on a massive dataset of over 15 trillion tokens from public sources
- Offers enhanced performance through a refined tokenizer and rigorous fine-tuning process
- Demonstrated strong performance, often preferred by human evaluators over competing models
- Designed to support over 30 languages, with plans for further multilingual improvements
- Part of Meta's ambitious plans, including the upcoming 400 billion parameter model
- Includes new security measures like Llama Guard 2, Cybersec Eval 2, and Code Shield
- Remains relatively compact and computationally efficient despite increased parameters
- May be open source, reflecting Meta's commitment to accessible AI technology
This major upgrade builds significantly upon Llama 2, with enhanced performance across key metrics. But Llama 3 is only one part of Meta's ambitious AI plans. They also announced the launch of Meta AI, an initiative focused on pushing the boundaries of artificial intelligence.
Understanding Llama models
The Llama models have gained a lot of attention in the AI community for their unique features and broad applications. Unlike models like GPT-4 and Claude, which are designed primarily for individual use, the Llama series has been widely adopted by developers and tech enthusiasts due to its affordability, speed, and versatility.
One key aspect that sets the Llama models apart is their open-source nature. This means developers can customize and fine-tune them for specific tasks, making Llama models a popular choice for leveraging the power of large language models (LLMs) without the high costs of proprietary models.
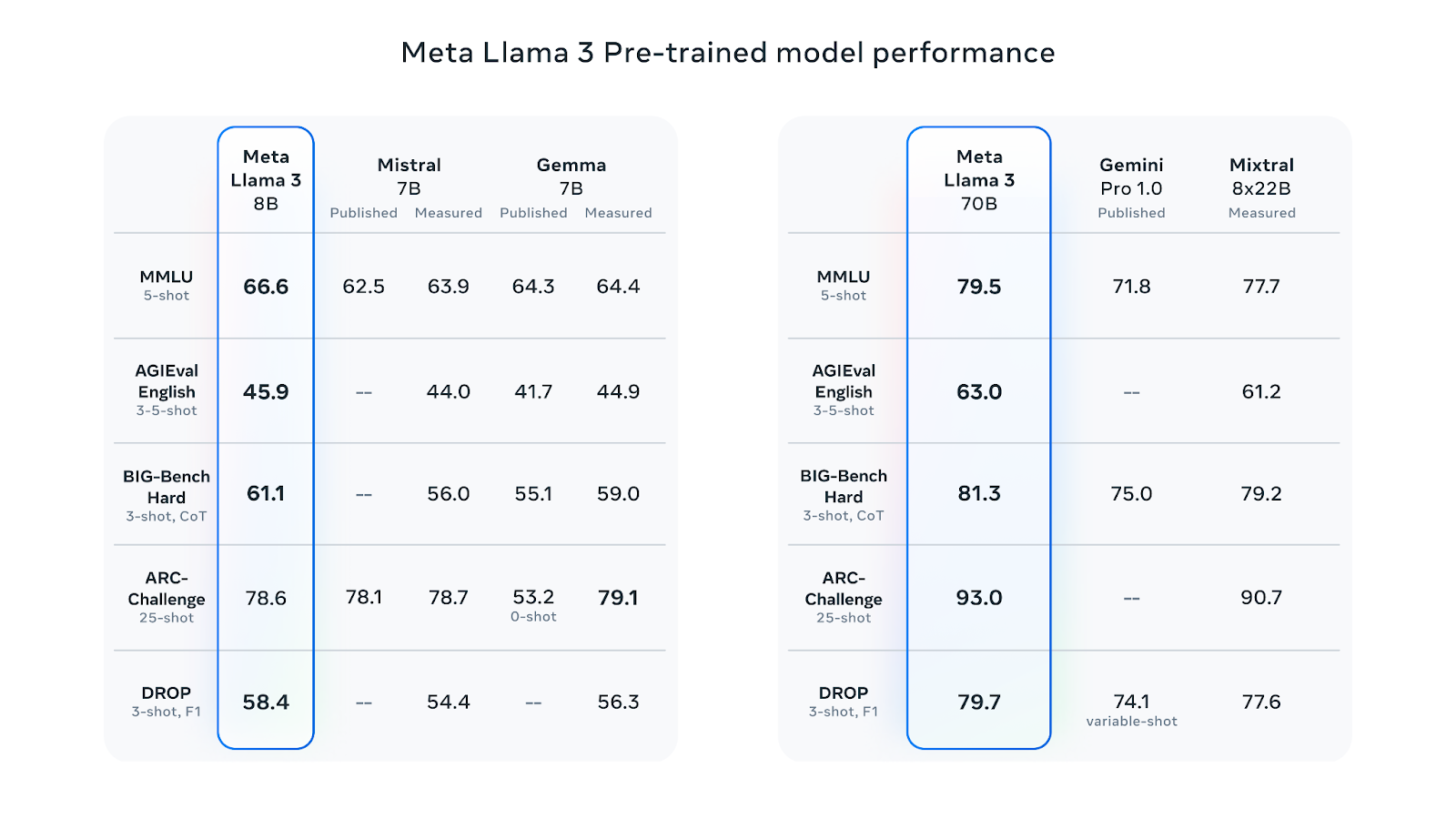
Meta's latest iteration, Llama 3, includes significant improvements. It has a refined tokenizer (a component that breaks down language into smaller units) that can handle a vocabulary of 128,000 tokens, making language processing more efficient and improving performance.
The training of Llama 3 involved a massive dataset of over 15 trillion tokens from publicly available sources – seven times larger than its predecessor Llama 2 and containing four times more code. This extensive training was combined with a rigorous fine-tuning process to maximize accuracy and efficiency.
But Meta didn't just focus on standard benchmarks. They also optimized Llama 3 for practical, real-world use cases. To achieve this, they created a new high-quality human evaluation set with 1,800 prompts spanning 12 critical areas like advice, brainstorming, question answering, coding, creative writing, and more. Importantly, this evaluation set is kept inaccessible even to Meta's own modeling teams to prevent overfitting.
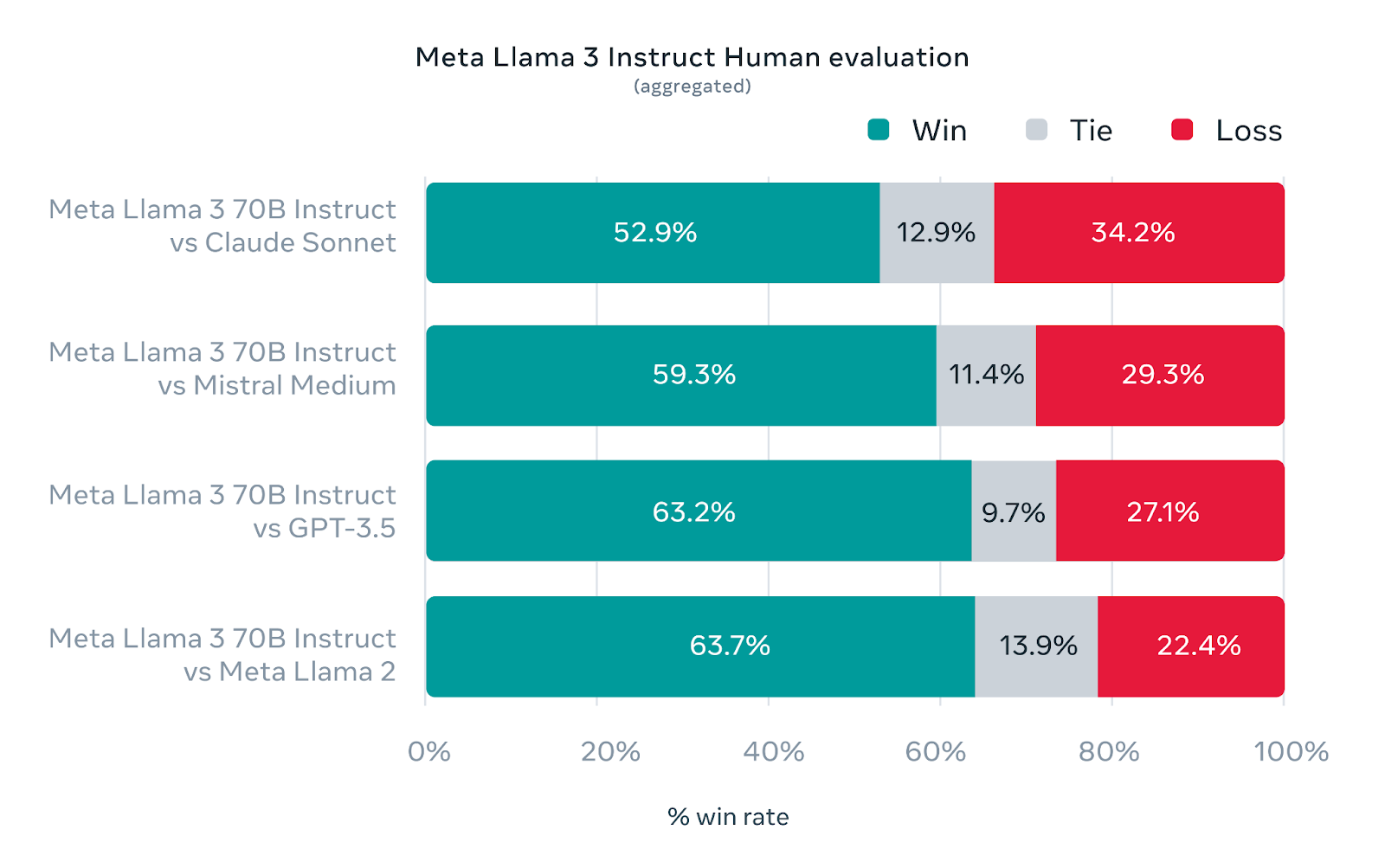
According to the data, Llama 3's 70B model has performed exceptionally well in these real-world scenarios. Human evaluators often preferred it over competing models, with Llama 3 achieving a win rate of 63.7% over Meta Llama 2, 63.2% over GPT-3.5, 59.3% against Mistral Medium, and 52.9% when compared to Claude Sonnet. This preference ranking by human evaluators suggests that Meta's pre-trained Llama 3 model has set a new standard for LLMs at this scale.
While earlier Llama models were primarily optimized for English, Llama 3 has been designed to support multiple languages, with training data encompassing over 30 languages. Although its multilingual capabilities may need further refinement, ongoing enhancements are expected to significantly improve this aspect.
Meta has even bigger plans in the works. They've announced the development of a highly anticipated model with over 400 billion parameters, set to be released in the coming months. This new model promises to support additional languages and offer expanded functionalities, including larger context windows for handling more complex queries.
To ensure the safety and security of these advanced models, Meta has introduced new measures like Llama Guard 2, Cybersec Eval 2, and Code Shield, designed to prevent misuse, security threats, and the generation of insecure code.
Despite the substantial increase in parameters, the Llama 3 models remain relatively compact, allowing them to deliver high-quality outputs with reduced computational demand. For example, an eight-billion parameter model in Llama 3 requires just 8GB of memory at 8-bit precision, with potential reductions using 4-bit precision.
While the decision to open-source the 400-billion-parameter version of Llama 3 hasn't been finalized, Meta's CEO Mark Zuckerberg has suggested it's unlikely to be restricted due to safety concerns. This openness reflects Meta's commitment to advancing AI technology in an accessible and beneficial way for the broader community.
As we look forward to these developments, it's clear that Meta is not just participating in the AI race but is striving to lead it, continuously innovating to enhance the capabilities and accessibility of its Llama models.
You can try now Llama 3 at OmniGPT!